主题
🎧 更喜欢听?试试本文的音频版本
给 AI 装上记忆系统:深度解读 GSW
0:000:00
写在前面
你有没有想过,为什么 AI 在回答问题时,有时候会"丢三落四"?明明文档里有完整的故事线,AI 却只能抓住零散的片段?
今天要介绍的 GSW(Generative Semantic Workspace,生成语义工作区)技术,正在改变这一切——它让 AI 拥有了类似人类的"情景记忆"能力!
GSW(Generative Semantic Workspace,生成语义工作区)是一种新型 AI 记忆架构,通过模拟人类大脑的海马体和新皮层机制,将零散信息组织成结构化的"世界模型",使 AI 能够理解事件的时间线、因果关系和完整叙事。
传统 RAG 的痛点
什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大语言模型访问外部知识库的技术框架,通过"检索-生成"两阶段流程回答用户问题。
RAG(检索增强生成)是目前主流的让 AI 访问外部知识的技术。简单来说:
文档 → 切成小块 → 存入数据库 → 用户提问 → 找相关的块 → AI 生成答案听起来挺好,但实际使用中会发现很多问题。
四大核心问题
1. 记忆碎片化 🧩
场景举例:你在读一本侦探小说,想问"凶手是怎么一步步暴露的?"
传统 RAG:
- 找到第 23 页:"发现了一把刀"
- 找到第 67 页:"张三有嫌疑"
- 找到第 102 页:"警察展开调查"
但这些碎片之间的联系呢?案件如何发展的?时间顺序是什么?全部丢失。
2. 无法追踪演变 📈
场景举例:一家公司的发展历程
2020 年:初创公司,5 人团队
2021 年:获得投资,扩张到 50 人
2022 年:上市,成为行业龙头
2023 年:并购竞争对手传统 RAG 的问题:
- 只能告诉你某个时间点的状态
- 无法理解"公司是如何一步步成长的"
- 丢失了发展的因果关系
3. 时空信息缺失 🗺️

场景举例:一个人物的行程
周一在北京开会
周三飞到上海谈项目
周五回到深圳总部传统 RAG:
- 可能只检索到"周三在上海"
- 不知道他之前在哪、之后去哪
- 无法判断行程是否合理
4. 无法建立完整叙事 📖
最致命的问题:传统 RAG 擅长回答"是什么",但很难回答:
- "为什么会这样?"
- "后来发生了什么?"
- "这件事的来龙去脉是什么?"
因为这些问题需要连贯的推理,而不是孤立的事实检索。
GSW:给 AI 装上"海马体"
人类是如何记忆的?
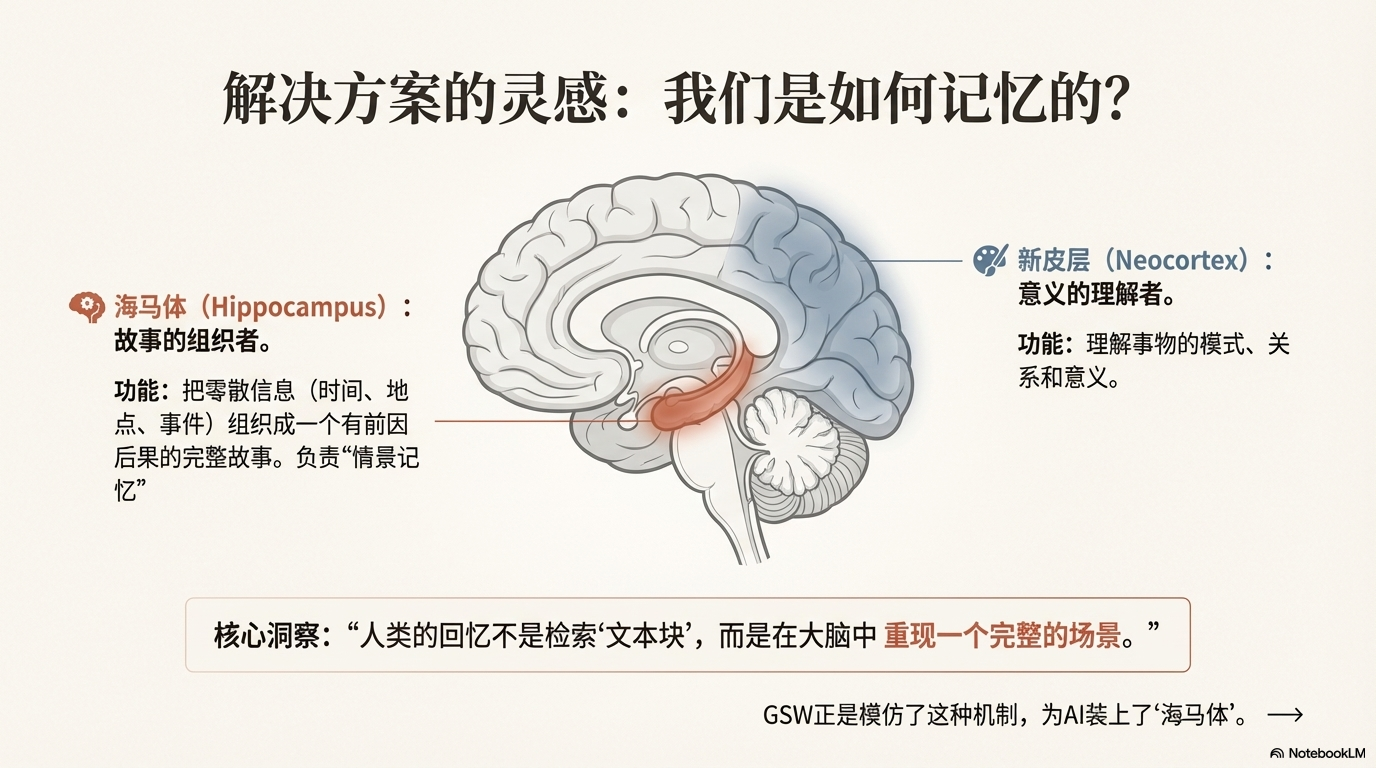
人类大脑有两个关键部分负责记忆:
🧠 海马体(Hippocampus)
- 负责把零散信息组织成故事
- 记住"什么时候"、"在哪里"发生了什么
- 连接不同事件,形成完整记忆
🎨 新皮层(Neocortex)
- 理解事物的意义
- 识别模式和关系
- 预测可能的发展
当你回忆昨天发生的事情时,大脑不是在检索"文本块",而是在重现一个完整的场景——时间、地点、人物、对话、情感,应有尽有。
GSW 的核心理念
GSW 模仿人类大脑,不再简单地检索文本片段,而是:
构建一个动态的、结构化的"世界模型"

就像你脑海中的记忆一样,GSW 为 AI 创建了一个内在的"世界",在这个世界里:
- 每个人物都有自己的故事线
- 每个事件都有时间和地点
- 所有信息都相互关联
- 随着阅读不断更新和演化
GSW 的工作原理
双核心架构
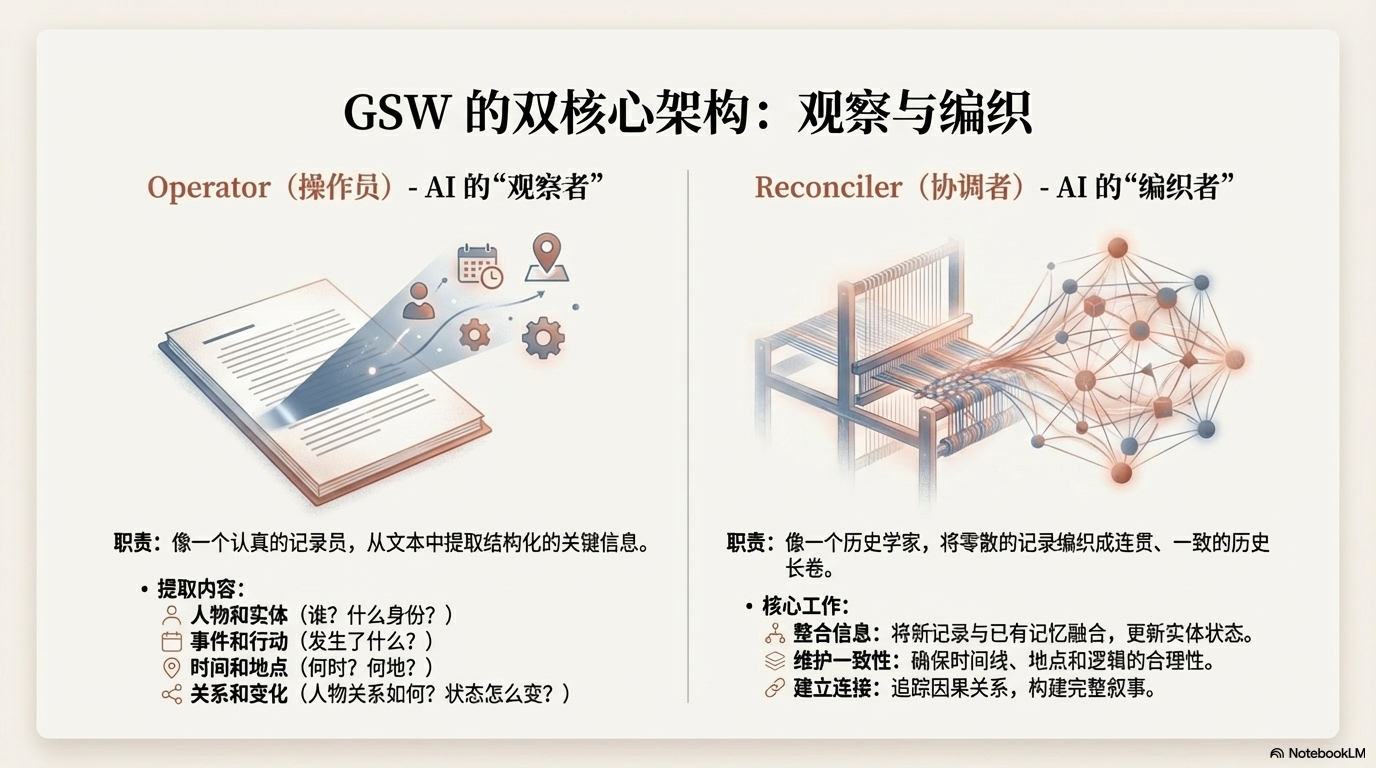
Operator(操作员)- AI 的"观察者"
职责:像一个认真的记录员,从文本中提取关键信息
它会记录什么?
人物和实体
- 谁出现了?
- 他们是什么身份?
- 处于什么状态?
事件和行动
- 发生了什么?
- 谁做的?
- 对谁做的?
时间和地点
- 什么时候发生的?
- 在哪里发生的?
关系和变化
- 人物之间是什么关系?
- 发生了什么变化?
举个例子:
原文:
"2024 年 3 月 15 日,在上海的新品发布会上,张总宣布公司完成 C 轮融资,估值达到 10 亿美元。"
Operator 提取:
实体:张总、公司
事件:宣布融资完成
时间:2024 年 3 月 15 日
地点:上海
关键信息:C 轮融资、估值 10 亿Reconciler(协调者)- AI 的"编织者"
职责:像一个历史学家,把零散的记录编织成完整的历史长卷
它做三件关键的事:
整合信息
- 把新信息和已有记忆结合
- 发现重复或矛盾的内容
- 更新实体的状态
维护一致性
- 确保时间线合理(不会出现"先死后生")
- 确保地点合理(不会"瞬间移动")
- 确保逻辑一致(不会自相矛盾)
建立连接
- 连接相关的事件
- 追踪因果关系
- 构建完整叙事
继续前面的例子:
假设后来又读到:
"2024 年 6 月,公司在北京开设了新的研发中心。"
Reconciler 的工作:
更新实体状态:
公司:
- 3 月:完成 C 轮融资(上海)
- 6 月:开设研发中心(北京)
建立连接:
融资完成 → 资金充足 → 扩张业务 → 开设新中心
维护时间线:
✓ 6 月在 3 月之后,时间合理
✓ 上海和北京都在中国,地理合理完整工作流程
让我们看看当你问 AI 一个问题时,GSW 是如何工作的:
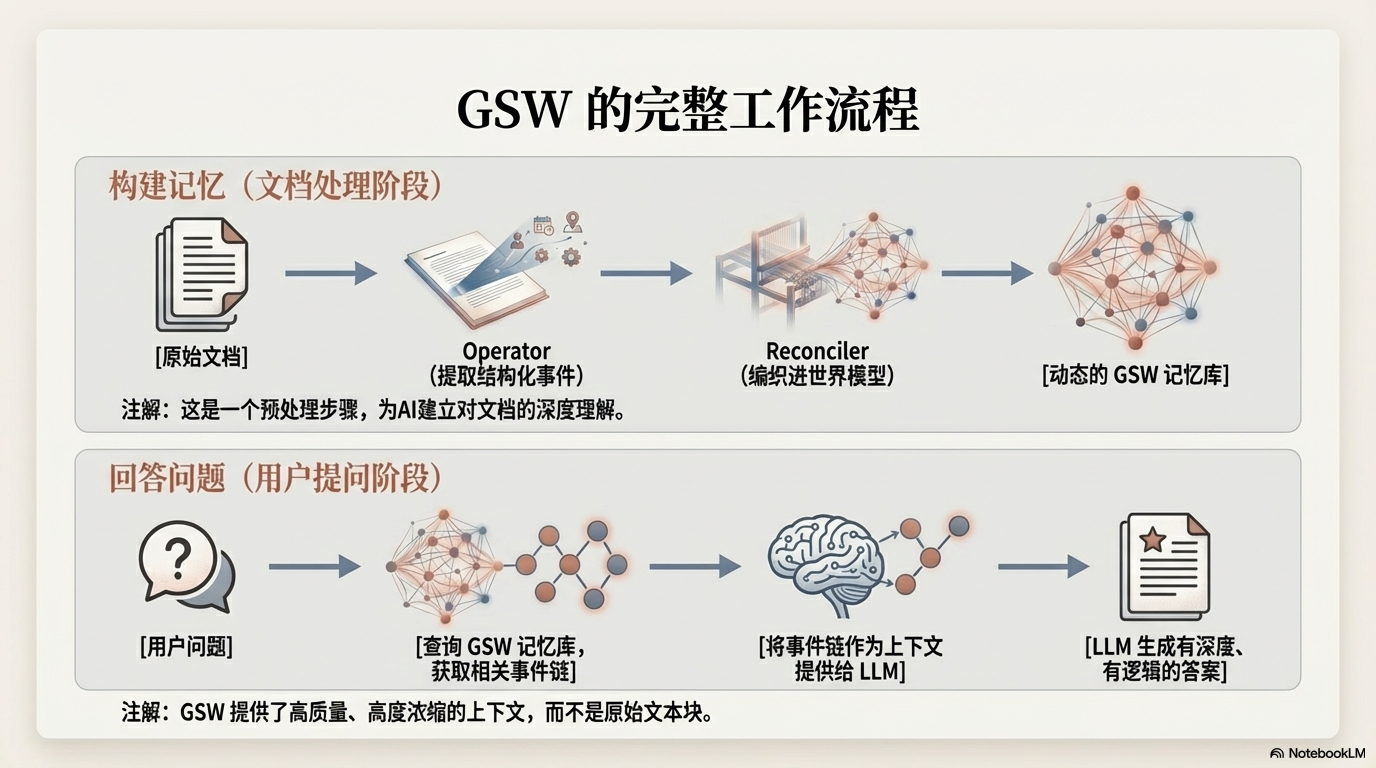
阶段一:构建记忆(处理文档时)
📄 读取文档
↓
👁️ Operator 观察记录
↓
🧩 生成局部记忆片段
↓
🔄 Reconciler 整合
↓
📚 更新全局记忆库阶段二:回答问题(用户提问时)
❓ 用户提问:"公司是如何成长的?"
↓
🔍 识别关键实体:"公司"
↓
📖 检索相关记忆:
- 3 月融资事件
- 6 月扩张事件
- 其他相关事件
↓
✨ 生成情景摘要:
"公司在 3 月完成融资后,获得资金支持,
随后在 6 月扩张业务..."
↓
🤖 AI 生成最终答案为什么 GSW 更强大?
对比案例 1:理解小说情节

问题:"主角的心态是如何变化的?"
传统 RAG 的回答:
检索到的片段:
- 第 50 页:"主角感到沮丧"
- 第 120 页:"主角变得坚强"
- 第 200 页:"主角找到了希望"
AI 的回答:
"主角经历了沮丧、坚强和希望的情绪。"
❌ 问题:
- 没有因果关系
- 不知道为什么变化
- 缺乏完整脉络
GSW 的回答:
GSW 构建的记忆:
第 50 页:主角失业 → 情绪:沮丧
第 80 页:主角遇到导师 → 获得指导
第 120 页:主角重新振作 → 情绪:坚强
第 180 页:主角找到新工作 → 事业:顺利
第 200 页:主角帮助他人 → 情绪:充满希望AI 的回答:
"主角的心态经历了明显的成长过程。起初因为失业而沮丧,但在第 80 页遇到导师后获得了人生指导。这次相遇成为转折点,使他在第 120 页重新振作,变得坚强。随着在第 180 页找到新工作,他的生活步入正轨,最终在第 200 页不仅找到了个人的希望,还开始帮助他人,展现出从受助者到助人者的成长。"
✅ 优势:
- 完整的时间线
- 清晰的因果关系
- 有转折点和关键事件
- 能看到成长轨迹
对比案例 2:分析商业决策

问题:"公司为什么会做出这个战略调整?"
传统 RAG 的回答:
检索片段:
- "公司宣布调整战略"
- "市场环境变化"
- "竞争对手施压"
AI 的回答:
"因为市场环境变化和竞争对手施压,公司调整了战略。"
❌ 问题:
- 笼统模糊
- 缺乏具体过程
- 看不到决策逻辑
GSW 的回答:
GSW 追踪的完整链条:
2023 Q1:竞争对手推出新产品 → 市场份额下降 5%
2023 Q2:公司内部展开讨论 → 发现技术落后
2023 Q3:调研报告显示用户需求变化
2023 Q4:董事会批准战略转型方案
2024 Q1:正式宣布战略调整AI 的回答:
"公司的战略调整是一个循序渐进的过程。2023 年第一季度,竞争对手推出新产品后,公司市场份额下降了 5%,这引起了管理层的警觉。随后在第二季度的内部讨论中,发现了公司技术上的短板。第三季度的用户调研进一步证实了市场需求的转变。经过充分准备,董事会在第四季度批准了转型方案,并在 2024 年第一季度正式对外宣布。这个决策是基于市场压力、内部反思和用户需求三方面因素的综合考量。"
✅ 优势:
- 完整的决策过程
- 多方面的原因分析
- 时间线清晰
- 逻辑链条完整
GSW vs 传统 RAG:一目了然
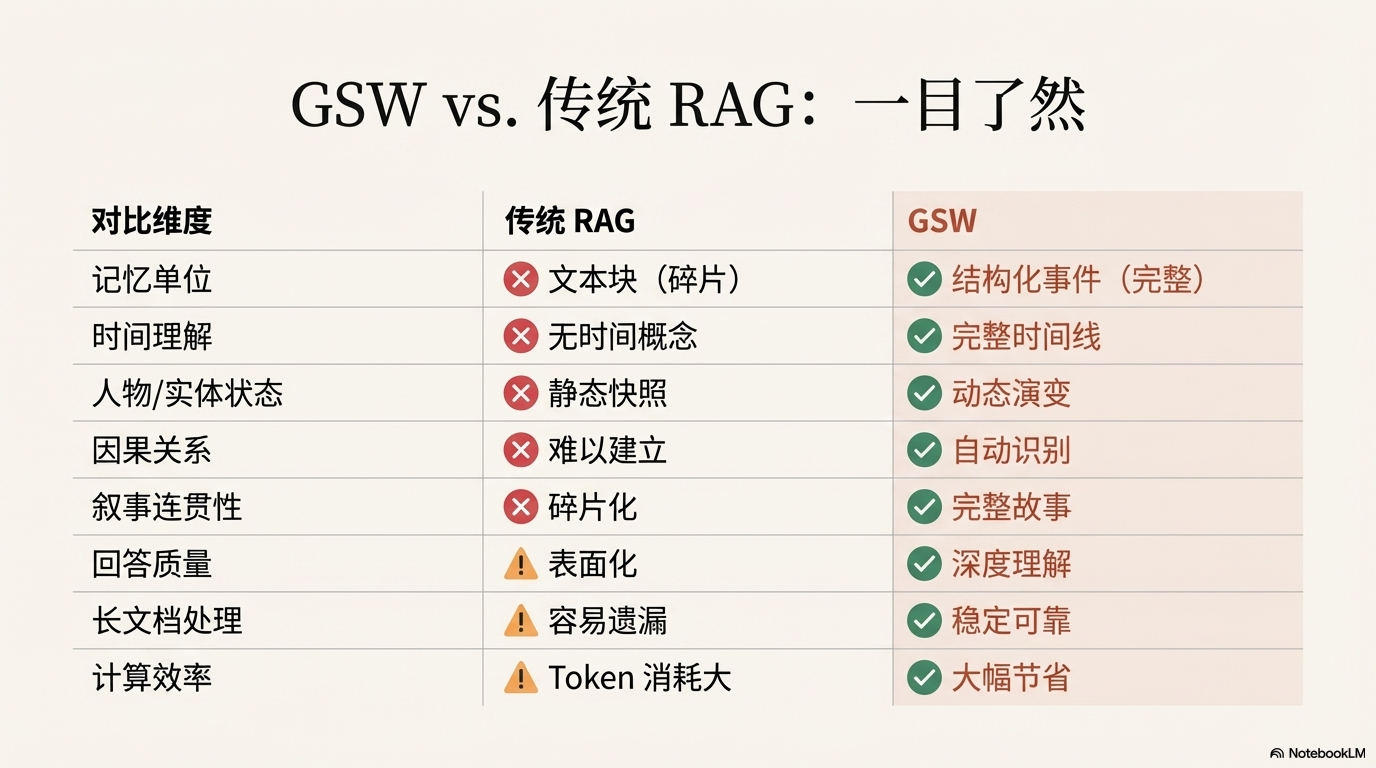
| 对比维度 | 传统 RAG | GSW |
|---|---|---|
| 记忆单位 | 文本块(碎片) | 结构化事件(完整) |
| 时间理解 | ❌ 无时间概念 | ✅ 完整时间线 |
| 地点追踪 | ❌ 无空间概念 | ✅ 地理位置追踪 |
| 人物状态 | ❌ 静态快照 | ✅ 动态演变 |
| 因果关系 | ❌ 难以建立 | ✅ 自动识别 |
| 叙事连贯性 | ❌ 碎片化 | ✅ 完整故事 |
| 长文档处理 | ⚠️ 容易遗漏 | ✅ 稳定可靠 |
| 回答质量 | ⚠️ 表面化 | ✅ 深度理解 |
| 计算效率 | ⚠️ Token 消耗大 | ✅ 节省 51% |
真实应用场景
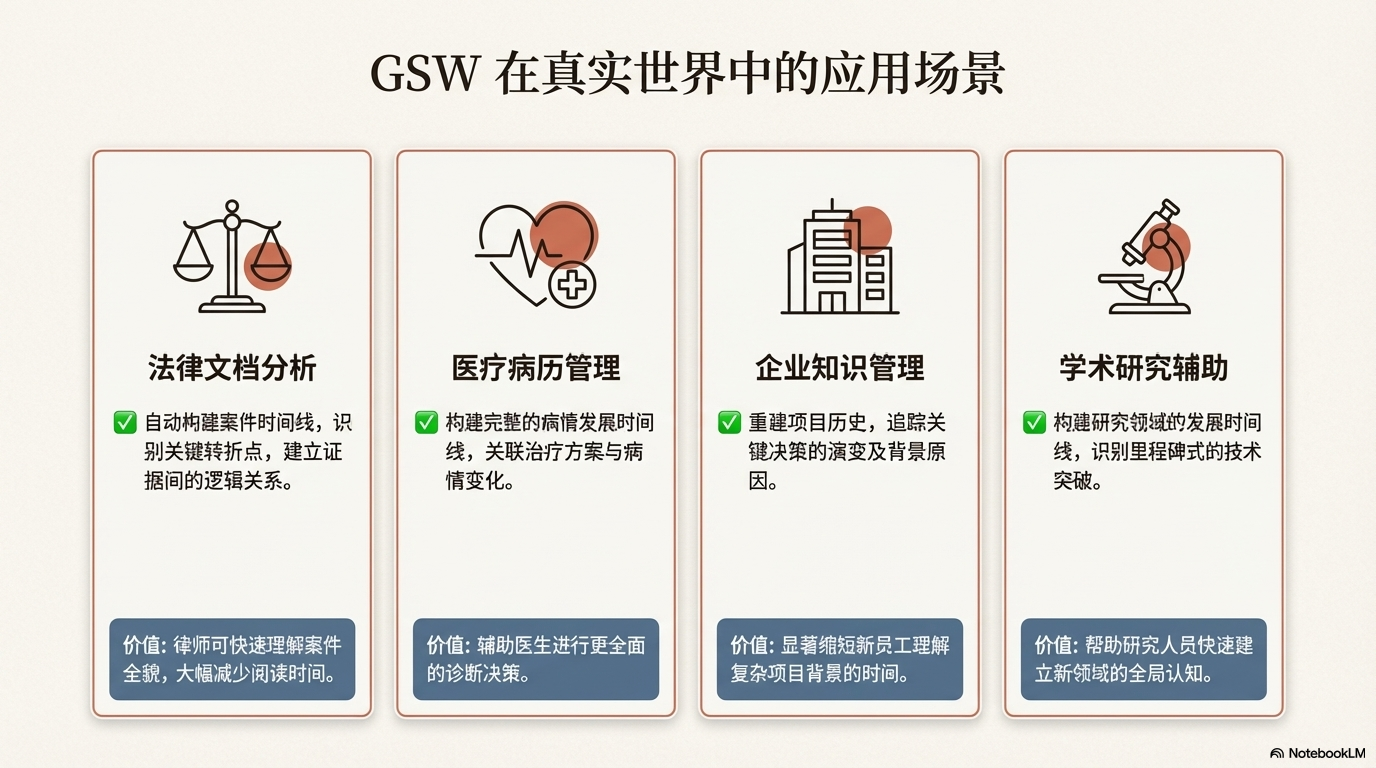
场景 1:法律文档分析
需求:理解一个复杂案件的来龙去脉
传统 RAG 的表现:
- 能找到各个时间点的证据
- 但难以理解事件的前因后果
- 容易遗漏关键的时间线细节
GSW 的优势:
- ✅ 自动构建案件时间线
- ✅ 追踪每个当事人的状态变化
- ✅ 识别关键的转折点
- ✅ 建立证据之间的逻辑关系
- ✅ 生成完整的案件叙事
💡 预期效果:律师可以快速理解案件全貌,大幅减少阅读时间。
场景 2:医疗病历管理
需求:追踪患者的治疗过程
传统 RAG 的表现:
- 能查到某次检查结果
- 但看不到病情发展趋势
- 难以关联不同时期的症状
GSW 的优势:
- ✅ 构建完整的病情发展时间线
- ✅ 追踪症状的演变过程
- ✅ 关联治疗方案和病情变化
- ✅ 识别有效的治疗措施
- ✅ 预测可能的病情发展
💡 预期效果:医生可以更全面地了解病史,辅助诊断决策。
场景 3:企业知识管理
需求:理解项目的历史沿革
传统 RAG 的表现:
- 能找到项目的各个文档
- 但不知道决策的演变过程
- 难以理解当时的背景和原因
GSW 的优势:
- ✅ 重建项目的完整历史
- ✅ 追踪关键决策的演变
- ✅ 保存决策背景和原因
- ✅ 连接相关的人员和事件
- ✅ 为新员工快速建立上下文
💡 预期效果:显著缩短新员工理解项目背景的时间。
场景 4:学术研究辅助
需求:梳理某个研究方向的发展脉络
传统 RAG 的表现:
- 能检索到相关论文
- 但难以理解研究的演进
- 无法看到技术的发展路径
GSW 的优势:
- ✅ 构建研究领域的发展时间线
- ✅ 追踪关键概念的演变
- ✅ 识别里程碑式的突破
- ✅ 连接不同研究之间的关系
- ✅ 发现研究的趋势和方向
💡 预期效果:研究人员可以快速建立新领域的全局认知。
场景 5:客户服务系统
需求:理解客户的历史问题和需求
传统 RAG 的表现:
- 能查到历史工单
- 但不知道问题的根源
- 难以提供连贯的服务
GSW 的优势:
- ✅ 追踪客户的完整历程
- ✅ 理解问题的演变过程
- ✅ 识别反复出现的问题
- ✅ 关联不同时期的需求
- ✅ 提供个性化的服务
💡 预期效果:提升客户满意度,加快问题解决效率。
实施建议
适合使用 GSW 的场景
✅ 强烈推荐:
- 需要理解长文档(>10 页)
- 需要追踪实体状态变化
- 需要建立时间线
- 需要因果推理
- 文档有清晰的叙事结构
⚠️ 谨慎评估:
- 文档很短(❤️ 页)
- 只需要简单的关键词检索
- 实时性要求极高(毫秒级)
- 预算非常有限
❌ 不太适合:
- 纯数值查询(如"今天天气几度?")
- 实时数据(股票价格、新闻快讯)
- 简单的FAQ问答
常见问题
Q1: GSW 会完全取代传统 RAG 吗?
答:不会完全取代,两者各有所长。 简单查询用传统 RAG 更快更便宜,复杂推理用 GSW 更准确更智能。建议根据具体场景选择,或者组合使用。
Q2: GSW 的准确率有多高?

答:GSW 在 EpBench 测试中达到 F1-score 0.850(State-of-the-Art)。 根据 UCLA 团队的论文数据:
论文实验数据:
- F1-score:0.850(State-of-the-Art)
- 召回率:比传统 RAG 基线提升约 20%
- Token 效率:查询时减少 51% 的上下文 Token
📊 以上数据来自 AAAI 2026 论文《Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces》
Q3: 我的文档不是小说,也适用吗?
答:完全适用,GSW 不仅限于小说类文档。 只要文档涉及"时间"、"人物"、"事件"的演变,GSW 都能发挥作用。
更适合的场景:
- 技术文档(追踪版本演变)
- 会议记录(追踪决策过程)
- 项目文档(理解项目历史)
- 客户档案(了解客户历程)
Q4: 如何评估 GSW 是否适合我的业务?

答:问自己三个问题,如果都是"是",强烈建议尝试 GSW。
我的用户是否经常问"为什么"和"怎么样"?
- 如果是,GSW 能提供更好的答案
我的文档是否超过 10 页且信息相互关联?
- 如果是,GSW 能更好地理解全局
理解上下文对我的业务是否关键?
- 如果是,GSW 能提供关键价值
如果三个问题都是"是",强烈建议尝试 GSW。
总结:记忆系统的革命

GSW 带来的不仅是技术改进,更是 AI 理解方式的革命:
从"检索"到"理解"
- 过去:AI 像一个图书管理员,只会找书
- 现在:AI 像一个学者,真正理解内容
从"碎片"到"完整"
- 过去:给你一堆拼图碎片
- 现在:给你完整的画面
从"静态"到"动态"
- 过去:只能看到快照
- 现在:能看到完整的电影
核心价值
对于企业(基于论文数据):
- 💰 减少 51% 的查询时 Token 消耗,降低推理成本
- ⚡ 复杂查询召回率提升约 20%
- 🎯 提供更具深度的情景化洞察
对于用户:
- 🧠 获得更智能的回答
- 📖 理解完整的故事
- ✨ 体验更自然的对话
对于行业:
- 🚀 推动 AI 向真正的智能进化
- 🌍 打开新的应用场景
- 💡 启发更多创新方向
写在最后
AI 的进化,本质上是让机器越来越像人类思考。
GSW 迈出了重要的一步——让 AI 拥有了"记忆"。不是机械的存储,而是有结构、有逻辑、有关联的真正的记忆。
未来的 AI 将不再是冰冷的工具,而是能够:
- 🤝 理解你的需求
- 🧠 记住完整的上下文
- 💡 提供深度的洞察
- 🎯 给出准确的答案
这不是 RAG 的终结,而是 AI 记忆系统的新开端。
延伸阅读
如果你想进一步了解 GSW 和相关技术,以下资源可能对你有帮助:
相关概念
| 概念 | 说明 | 学习建议 |
|---|---|---|
| RAG | 检索增强生成的基础技术 | 了解基本原理后对比 GSW 的改进 |
| 向量数据库 | 存储和检索语义信息的基础设施 | Pinecone、Milvus、Chroma 等 |
| 知识图谱 | 结构化知识表示方式 | 理解实体关系建模思想 |
| 大语言模型 | GSW 的核心计算引擎 | GPT、Claude 等模型的能力边界 |
技术资源
- LangChain 官方文档 - RAG 和 AI 应用开发框架
- LlamaIndex 官方文档 - 数据连接和检索框架
- OpenAI Cookbook - 官方最佳实践示例
进阶话题
- 多模态 RAG - 图像、音频、视频内容的检索增强
- Agent 架构 - 自主规划和执行任务的 AI 系统
- 长上下文模型 - Gemini、Claude 等百万级 Token 窗口模型的应用
📚 论文引用
本文核心内容基于以下学术论文:
Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces
作者:Shreyas Rajesh, Pavan Holur, Chenda Duan, David Chong, Vwani Roychowdhury
机构:University of California, Los Angeles (UCLA)
发表:AAAI 2026 (Oral Paper)